
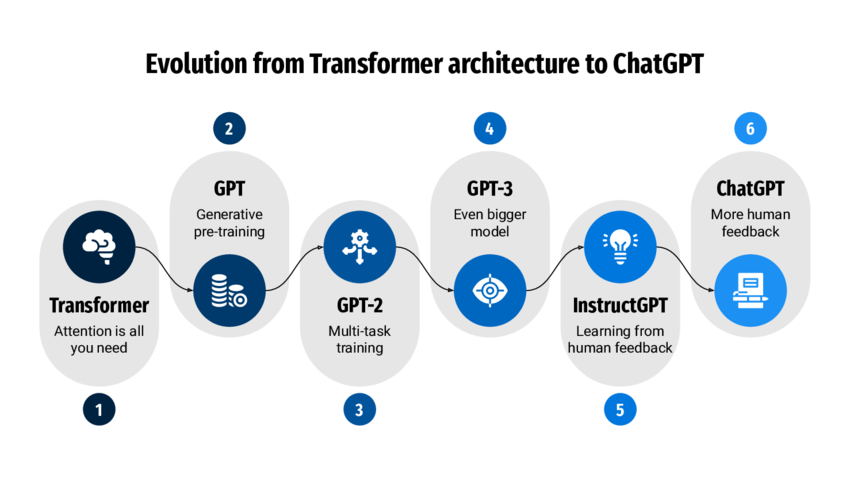
The Evolution of Language Generative AI: GPT, GPT-2, GPT-3, and InstructGPT
#You may find the reproduce work here. (If you need any )
1.Introduction
In recent years, the field of artificial intelligence has undergone a revolution, at the heart of which are the increasingly powerful Generative Pre-trained Transformer models, known as GPT, developed by leading technology companies like Google and OpenAI. From the first GPT in 2018, to GPT-2, and then to GPT-3 in 2020, followed by InstructGPT, these models have not only pushed the boundaries of natural language processing but have also drastically changed the way we interact with machines.
The original GPT model introduced the Transformer architecture, which optimized the processing of textual data through self-attention mechanisms, allowing the model to capture deep linguistic structures and meanings from vast amounts of text. Its pre-training approach, which involves training on a broad corpus before fine-tuning for specific tasks, significantly enhanced the model’s versatility and efficiency.
With the release of GPT-2, OpenAI significantly increased the scale of the model, introducing 1.5 billion parameters, more than ten times the number of its predecessor. This expansion not only enhanced the model’s language understanding capabilities but also enabled it to generate longer, more coherent texts persuasive across various styles and themes. The success of GPT-2 demonstrated the tremendous potential of large-scale language models in unsupervised learning.
GPT-3 reached an unprecedented scale with 175 billion parameters. It is capable of performing text generation, language translation, question-answering, summarization, and other complex language tasks, demonstrating near-human capabilities. Additionally, GPT-3’s introduction of “few-shot learning,” the ability to perform tasks with minimal task-specific training, using just a few examples, greatly expanded the model’s range of applications.
The latest model, InstructGPT, is further optimized from GPT-3 and is specifically designed to respond to human instructions. This improvement means that the model is more precise in understanding and executing specific commands, making interactions with AI more intuitive and efficient. The development of InstructGPT marks a significant advancement in human-machine interaction methods, showcasing the future trend of customized AI applications.
Through this blog post, we will explore in detail the developmental journey of these models and their technical details, as well as how these advancements are gradually changing the way we work and live. Starting from the original GPT, we have gone through several phases of development, each marked by technological breakthroughs and innovative ideas, ultimately shaping the intelligent conversational systems we rely on today.
2.GPT-1
In 2018, the field of NLP was primarily in a phase where deep learning approaches were centered around word2vec and crafting custom deep models for specific tasks. Although pre-trained models like ELMo and BERT had already emerged, their impact was not yet profound. Meanwhile, the rise of deep learning technologies provided new possibilities for handling large datasets. In 2017, researchers from Google published the paper “Attention Is All You Need,” introducing the transformer architecture for the first time. This new network structure, through its use of self-attention, could effectively process sequential data, particularly excelling over traditional RNNs and LSTMs in handling long-distance dependencies. Building on the transformer’s foundation, and incorporating the pre-training and fine-tuning approaches used in previous models, GPT-1 was developed.(Radford, Narasimhan, Salimans, and Sutskever, 2018)
2.1 Model Structure
During the pre-training phase, GPT selects the decoder part of the transformer as its main module. The transformer is a feature extraction model proposed by Google in 2017. GPT is constructed by stacking multiple layers of transformers to form the entire pre-training model structure.
Assuming there is a text with each word denoted as \(u_i\), GPT uses the standard language model objective function to maximize the following likelihood function:
\[L_1(U) = \sum_{i} \log P(u_i \mid u_{i-k}, \dots, u_{i-1}; \Theta)\]Specifically, it predicts the probability of each word \(u_i\), based on the words from \(u_{i-k}\) to \(u_{i-1}\), and the model \(\Theta\). Here, \(k\) represents the context window size; theoretically, the larger \(k\) is, the more context information the model can access, enhancing the model’s capabilities.
The model embeds input \(U\) into features to get the input \(h_0\) for the first layer of the transformer, then goes through multiple layers of transformer encoding, and uses the output of the last layer to obtain the current predicted probability distribution:
\[h_0 = UW_e + W_p \\ h_l = \text{transformer\_block}(h_{l-1}) \\ P(u) = \text{softmax}(h_n W_e^T)\]where \(W_e\) is the word embedding matrix, \(W_p\) is the position embedding matrix, \(h_l\) is the output of the \(l\)-th layer of the transformer, \(h_n\) is the output of the last layer of the transformer, and \(n\) is the number of layers.
During the fine-tuning phase, given an input sequence from \(x_1\) to \(x_m\) and a specific downstream task label, the model predicts the probability of \(y\) by inputting the sequence into the pre-trained model, obtaining features \(h_l^m\) of the last token \(x^m\) from the last transformer layer, and then passing it through a prediction layer to get the probability distribution for the corresponding label:
\[P(y \mid x^1, \dots, x^m) = \text{softmax}(h_l^m W_y)\]The objective function for the fine-tuning stage is:
\[L_2(U) = \sum_{(x,y)} \log P(y \mid x^1, \dots, x^m)\]The best results are obtained by joint training of the two objective functions, hence the final objective function is:
\[L_3(U) = L_2(U) + \lambda \cdot L_1(U)\]Compared to RNNs, the Transformer architecture features more structured memory units to address long-distance dependencies and handle longer text sequences, enhancing the robustness of the learned features across various tasks. Originally designed for seq2seq tasks, the Transformer model consists of both an encoder and a decoder; the primary difference is that the encoder can access all information in the sequence—both prior and subsequent context—while the decoder, due to its masking mechanism, can only access its own and preceding text information.
The GPT model employs the Transformer’s decoder part, precisely because its pre-training objective is the standard language model objective function, which allows the model to consider only the preceding context when predicting a word, without referencing the subsequent context. In contrast, BERT during its pre-training does not use the standard language model as its objective but opts for a masked language model, which enables it to see all contextual information around a word, similar to a cloze task; therefore, BERT uses the Transformer’s encoder component.
Although GPT may not perform as well as BERT on some tasks, its potential for effectively predicting future information may prove greater in the long run. OpenAI’s persistent use of the standard language model objective for pre-training, as evidenced by the impressive results of GPT-3 and subsequent ChatGPT, has proven to be both visionary and effective.
2.2 Model Training
In terms of training data, the original GPT model utilized the BooksCorpus dataset, which contains about 5 GB of text with over 74 million sentences. This dataset comprises approximately 7,000 independent books spanning diverse genres. The primary advantage of selecting this dataset is that book texts often include numerous high-quality, lengthy sentences, which ensures that the model can learn long-distance dependencies.
Some key parameters of the model include:
| Parameters | Values |
|---|---|
| layers | 12 |
| feature dimension | 768 |
| head | 12 |
| total parameters | 1.17B |
2.3 Downstream Tasks Fine-tuning
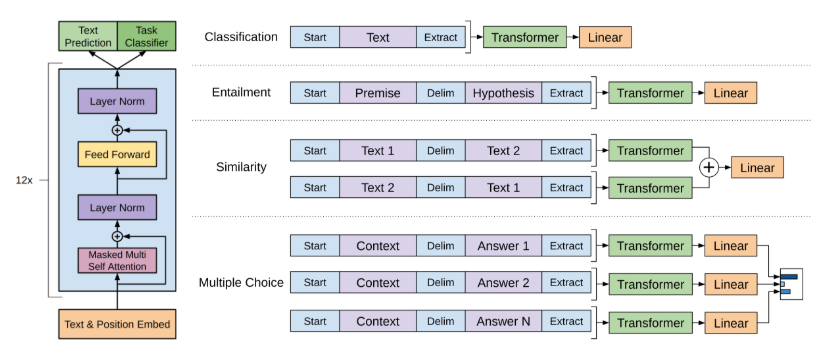
As illustrated, the application of the GPT model to four common NLP tasks (text classification, textual entailment, text similarity, and question answering) involves specific constructions for input sequences and designs for the prediction layer.
In general, the sequences are manipulated by adding special “Start” and “Extract” tokens to signify the beginning and end of sequences, respectively, and a “Delim” token is used as necessary to denote separation between segments. In practice, these labels (“Start/Extract/Delim”) are represented by specific special symbols. Based on the constructed input sequence for each downstream task, the pretrained GPT model is used for feature encoding, followed by predictions using the feature vector of the last token in the sequence.
It is evident that regardless of how the input sequences or prediction layers vary across different tasks, the core feature extraction module remains constant, demonstrating excellent transferability. This consistency ensures that the deep learning model can adapt to various tasks efficiently without requiring fundamental changes to its architecture.
2.4 Summary
Here are several point of the GPT-1:
Firstly, it was among the earliest works to propose the use of the pre-train + fine-tuning paradigm in NLP tasks.
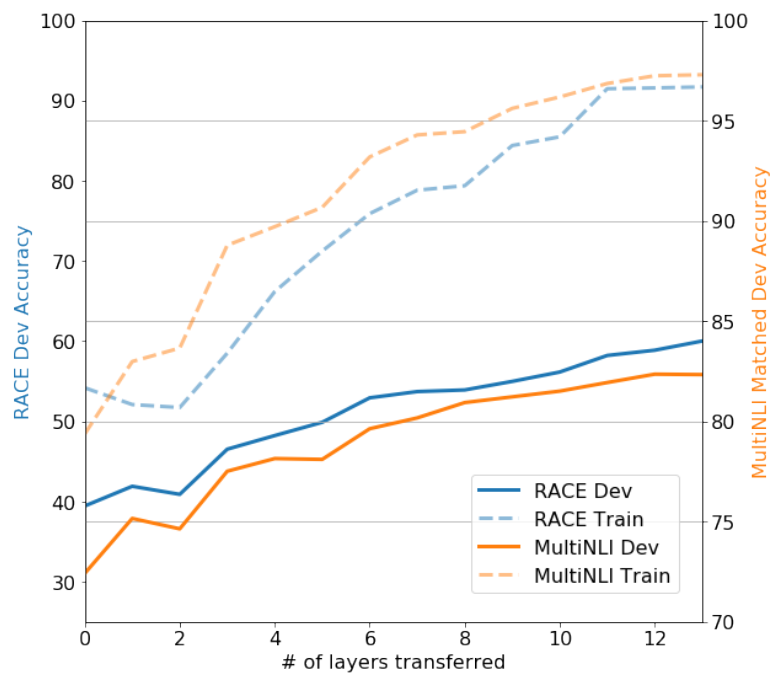
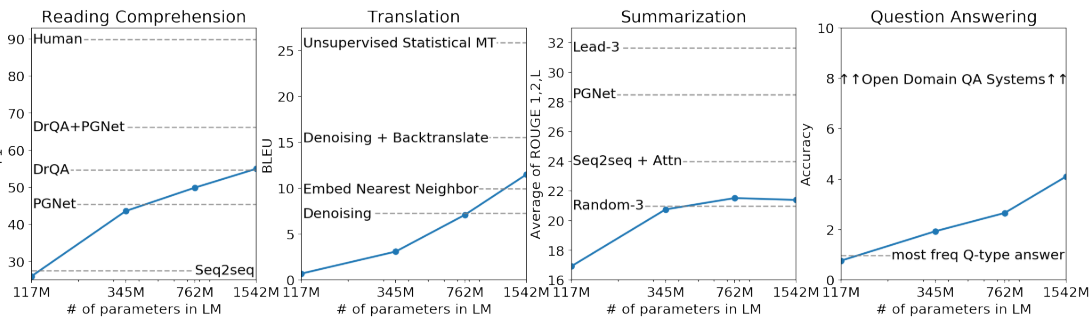
Secondly, GPT’s experiments demonstrated that the model’s accuracy and generalization capabilities continuously improve with the addition of more decoder layers, and there is still room for improvement, as illustrated below:
Thirdly, the pre-trained model possesses zero-shot capabilities, which can be progressively enhanced with ongoing pre-training, as shown in the following graph:
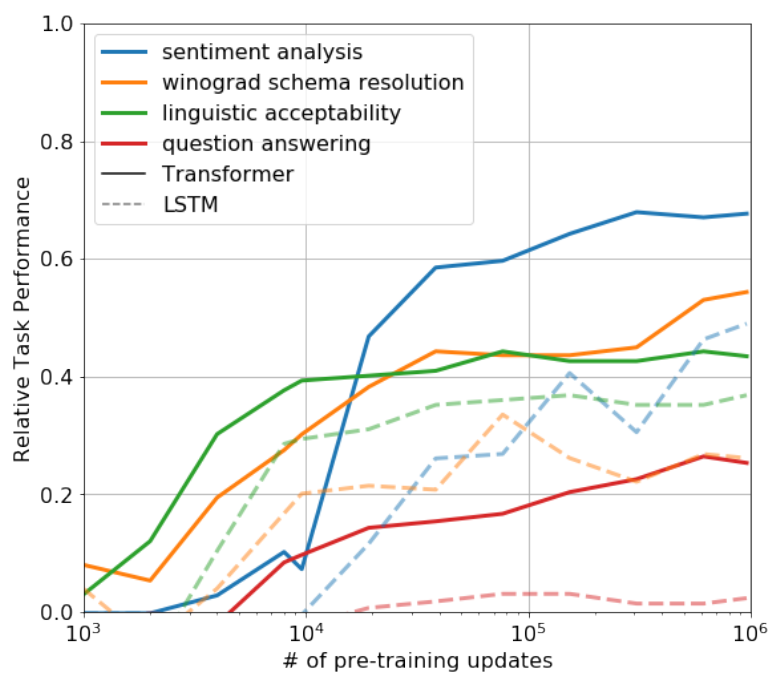
To further validate the zero-shot capabilities, OpenAI launched GPT-2 one year after the introduction of GPT-1.
3. GPT-2
Just one year later, OpenAI published the paper on GPT-2 titled “Language Models are Unsupervised Multitask Learners.”(Radford, Wu, Child, Luan, Amodei and Sutskever, 2019). The concept of multitasking in the title differs from the conventional understanding of multitasking in supervised learning. Here, it primarily refers to the model’s ability to transfer knowledge learned from large-scale data directly across multiple tasks without the need for additional task-specific data. This introduces the main premise of GPT-2: zero-shot learning.
Both GPT-1 and BERT, prevalent in NLP tasks, follow the pre-train + fine-tuning approach, which still requires a certain amount of supervised data for downstream tasks and additional model components for making predictions, thus incurring significant manual intervention costs. GPT-2 aims to completely resolve this issue through zero-shot learning, eliminating the need for additional labeled data or further model training when transitioning to other tasks.
In GPT-1, downstream tasks required modifications to the input sequences for different tasks, including the addition of special identifiers like start, delimiter, and end symbols. However, under the zero-shot premise, we cannot add these identifiers based on varying downstream tasks because the model will not recognize these special markers without additional fine-tuning. Therefore, under zero-shot conditions, the input sequences for different tasks should look the same as the texts seen during training, which means using natural language forms for inputs. For instance, the input sequences for the following two tasks are modified as follows:
Machine Translation Task: translate to french, { english text }, { french text }
Reading Comprehension Task: answer the question, { document }, { question }, { answer }
The authors believe that when a model has substantial capacity and the data is sufficiently rich, it can accomplish other supervised learning tasks merely through the learning capabilities of the language model, without fine-tuning on downstream tasks. This approach can provide the model with a richer array of data and training experiences.
3.1 Model Structure
In terms of model structure, the overall framework of GPT-2 is the same as GPT-1, but with several adjustments. These adjustments are more considered as training tricks rather than innovations of GPT-2, specifically:
Changed post-layer normalization (post-norm) to pre-layer normalization (pre-norm);
An additional layer normalization is added after the last self-attention layer of the model;
Adjusted the initialization method of parameters, scaling according to the number of residual layers, with a scaling ratio of \(1:\sqrt[]{n}\) ;
Expanded the maximum length of the input sequence from 512 to 1024.
The differences between post-norm and pre-norm can be referenced in “Learning Deep Transformer Models for Machine Translation.”(Wang et al., 2019)。The main difference between the two is that post-norm places the layer normalization after the residual layer in each transformer block, whereas pre-norm positions the layer normalization at the entry point of each block, as illustrated in the diagram below:
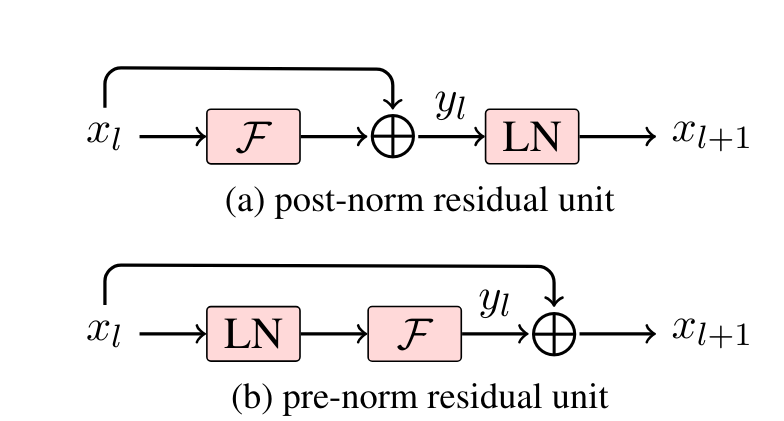
The main reason for the aforementioned adjustments in GPT-2 is that as the number of layers in the model increases, the risks of gradient vanishing and gradient exploding become more significant. These adjustments help to reduce the variance changes between layers during the pre-training process, stabilizing the gradients.
Ultimately, GPT-2 offers four different scales of models: (Among them, the 117M parameter model is equivalent to the GPT-1 model, and the 345M parameter model is designed to match the contemporary BERT-large model)

3.2 Training Data and Experimental Results
In terms of training data, to ensure effective zero-shot capabilities, the dataset must be sufficiently large and broad. Therefore, GPT-2 specifically crawled a vast amount of web text data, resulting in a dataset called WebText. It selected high-quality posts from Reddit, ultimately obtaining 45 million web links and 8 million valid text documents, with a corpus size of 40 GB.
Experimentally, since zero-shot learning is an unsupervised method, it is compared with other unsupervised methods. Although GPT-2 achieved certain improvements over other unsupervised algorithms in many tasks, demonstrating the capability of zero-shot learning, it still fell short of supervised fine-tuning methods in many respects. This may also be one reason why GPT-2 did not have as significant an impact at the time.
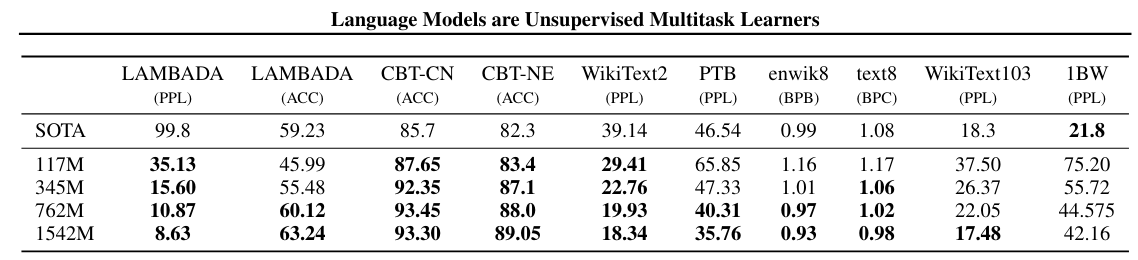
3.3 Conclusion
The main differences:
| GPT-2 | GPT-1 | |
|---|---|---|
| Method | zero-shot | pre-train + fine-tuning |
| Training Data | 40 GB | 5 GB |
| Total Parameters | 15B | 1B |
| Structure modification | layer Norm and initialization | Basic |
| Training Parameter | batch_size:512 context_window: 1024 | batch_size:64 context_window: 512 |
4. GPT-3
Although GPT-2’s zero-shot learning was highly innovative, its mediocre performance meant that it did not have a significant impact in the industry. The OpenAI team, aiming to mimic human learning methods, where only a few examples are needed to master a task, proposed the state-of-the-art GPT-3, originally described in the paper titled “Language Models are Few-Shot Learners.”(Brown et al., 2020). Here, “few-shot” does not refer to the previous approach of using a small number of samples for fine-tuning on downstream tasks, because with the scale of parameters in GPT-3, even the cost of fine-tuning is prohibitively high.
4.1 Model Structure
In terms of model architecture, GPT-3 continues to use the GPT model structure but introduces the sparse attention module from Sparse Transformers.
The difference between sparse attention and traditional self-attention (called dense attention) is as follows:
- Dense attention: Attention is calculated between every pair of tokens, with a complexity of \(O(n²)\).
- Sparse attention: Each token calculates attention only with a subset of other tokens, reducing the complexity to \(O(n*logn)\).
Specifically, in sparse attention, attention is set to zero for all tokens except those within a relative distance of k and those at distances of k, 2k, 3k,… as illustrated in the diagram below:
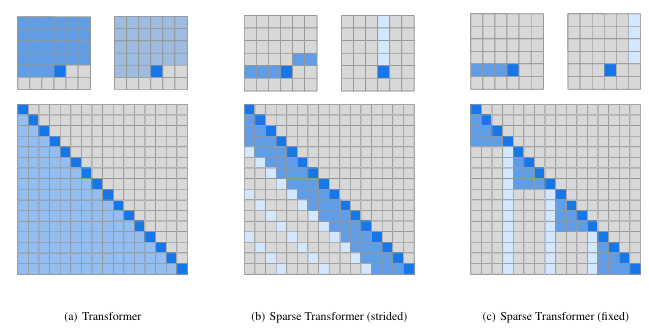
The benefits of using sparse attention primarily include the following two points:
It reduces the computational complexity of the attention layer, saving on memory usage and processing time, thereby enabling the handling of longer input sequences. It features a pattern of “local focused attention and distant sparse attention,” meaning there is more focus on closely related contexts and less on distant ones. For more details on sparse attention, refer to “Generating Long Sequences with Sparse Transformers.”(Child et al., 2019)
4.2 Downstream Task Evaluation
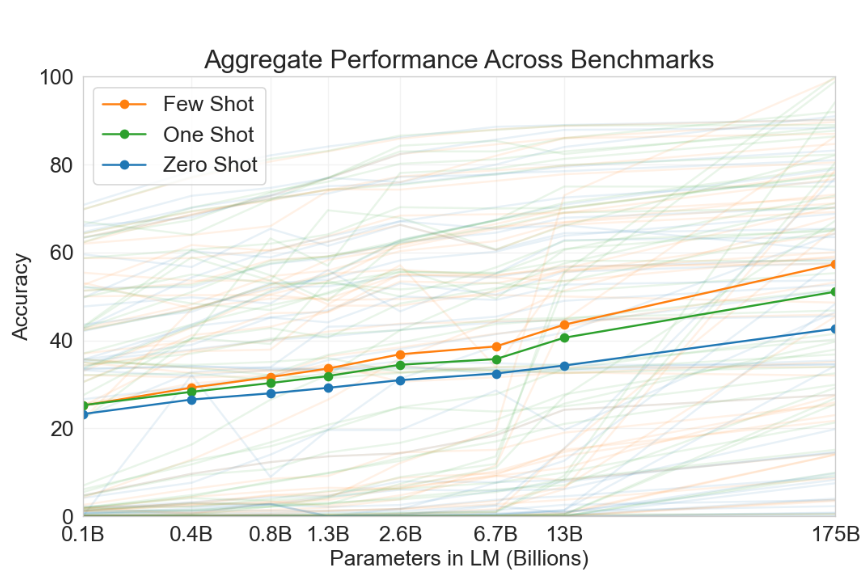
GPT-3 combines features from versions 1 and 2 in its evaluation and prediction for downstream tasks, offering three distinct approaches:
Zero-shot: Uses only the natural language description of the current task, with no gradient updates;
One-shot: Uses the natural language description of the current task along with a single simple input-output example, with no gradient updates;
Few-shot: Uses the natural language description of the current task along with a few simple input-output examples, with no gradient updates.
The few-shot approach is also known as in-context learning. Although it, like fine-tuning, requires some supervised labeled data, the differences between them are:
- In-context learning requires significantly fewer data points (10 to 100) compared to the typical data volumes needed for fine-tuning.
4.3 Training Data
Due to the increased model size of GPT-3, it was necessary to expand the training data to match the larger model and enable it to perform effectively.
GPT-3 utilized multiple datasets, with the largest being CommonCrawl, which comprised raw, unprocessed data amounting to 45TB. Although the use of this dataset was considered during the development of GPT-2, it was initially deemed too unclean for use. However, the significant increase in the model size of GPT-3 led to a greater demand for data volume, prompting a reconsideration of this dataset. Therefore, additional data cleaning efforts were necessary to ensure the quality of the data.
Data processing primarily involved the following steps:
- Training a logistic regression (LR) classification algorithm using high-quality data as positive examples to initially filter all documents from CommonCrawl;
- Utilizing publicly available algorithms for document deduplication to reduce data redundancy;
- Incorporating known high-quality datasets; “High-quality data” refers primarily to the data used by BERT, GPT, and GPT-2. After processing, the final dataset used was approximately 570GB.
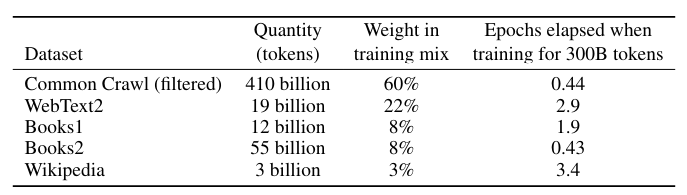
As illustrated in the experiments, data from different datasets was sampled at specific ratios, which were not solely based on the original volumes of data; otherwise, most of the sampled data would have been from CommonCrawl. Despite its significant volume—being hundreds of times larger than the other datasets—CommonCrawl data constituted 60% of the final sample, with the remaining 40% being high-quality data, ensuring better overall data quality.
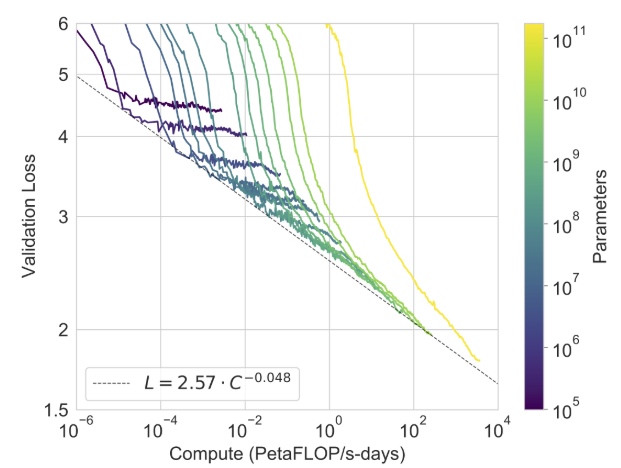
Additionally, their work demonstrated the relationship between computational power and changes in validation loss, indicating that linear improvements in task performance often require exponential increases in model size and data requirements.
4.4 The Limitations of GPT-3
Despite the impressive accomplishments of GPT-3, the paper maintains a rigorous academic approach by objectively analyzing its limitations:
- Text Generation Issues: For longer texts, GPT-3 tends to repeat phrases, contradict earlier parts, and struggle with logical transitions.
- Model and Structural Limitations: There are inherent limitations in using a unidirectional autoregressive language model, particularly for tasks like fill-in-the-blank text tasks. Considering both the preceding and following contexts might improve performance.
- Uniform Treatment of Corpus Words: During training, all words, including function words and meaningless ones, are treated equally. This results in substantial computational effort spent on less informative parts of the data, which does not prioritize learning effectively.
- Low Sample Efficiency: Training the model nearly requires using all available text data on the internet, a process that is far more resource-intensive compared to human learning methods, highlighting a major area for improvement in AI efficiency.
- Learning vs. Memorizing: It is unclear whether GPT-3 is genuinely learning or merely memorizing given the extensive data it processes. This distinction is crucial for understanding how AI can be improved to more closely mimic human learning.
- High Costs: The operational and training costs of GPT-3 are prohibitively high, limiting its accessibility and practicality.
- Lack of Interpretability: Like many deep learning models, GPT-3 lacks interpretability, which makes it difficult to understand how it makes decisions internally.
- Data Bias: The model’s performance is heavily dependent on its training data, which can introduce various biases into its outputs.
These issues underline the challenges that lie in enhancing AI’s efficiency, reducing its operational costs, and improving its decision-making transparency.
4.5 Conclusion
The main differences:
| GPT-3 | GPT-2 | |
|---|---|---|
| Method | few-shot | Zero-shot |
| Training Data | 45TB (570GB after clean) | 40 GB |
| Total Parameters | Maximum 1750 B | Maximum 15 B |
| Structure modification | Sparse Attention Module | layer Norm and initialization |
5. InstructGPT
Although GPT-3 has shown remarkable capabilities in various NLP tasks and text generation, it still generates biased, unrealistic, and harmful content that can have negative social impacts. Moreover, often it does not communicate in ways that humans prefer. In this context, OpenAI introduced the concept of “Alignment,” which means that the model’s outputs are in line with human true intentions and conform to human preferences. Thus, to make the model outputs more aligned with user intentions, the InstructGPT initiative was launched(Ouyang et al., 2022).
InstructGPT has set three primary goals for an idealized language model:
- Helpful (they should help the user solve their task),
- Honest (they shouldn’t fabricate information or mislead the user), and
- Harmless (they should not cause physical, psychological, or social harm to people or the environment).
5.1 Model Structures and Methods
InstructGPT primarily adopts a three-step approach: Supervised Fine-Tuning (SFT), training a reward model, and Reinforcement Learning from Human Feedback (RLHF).
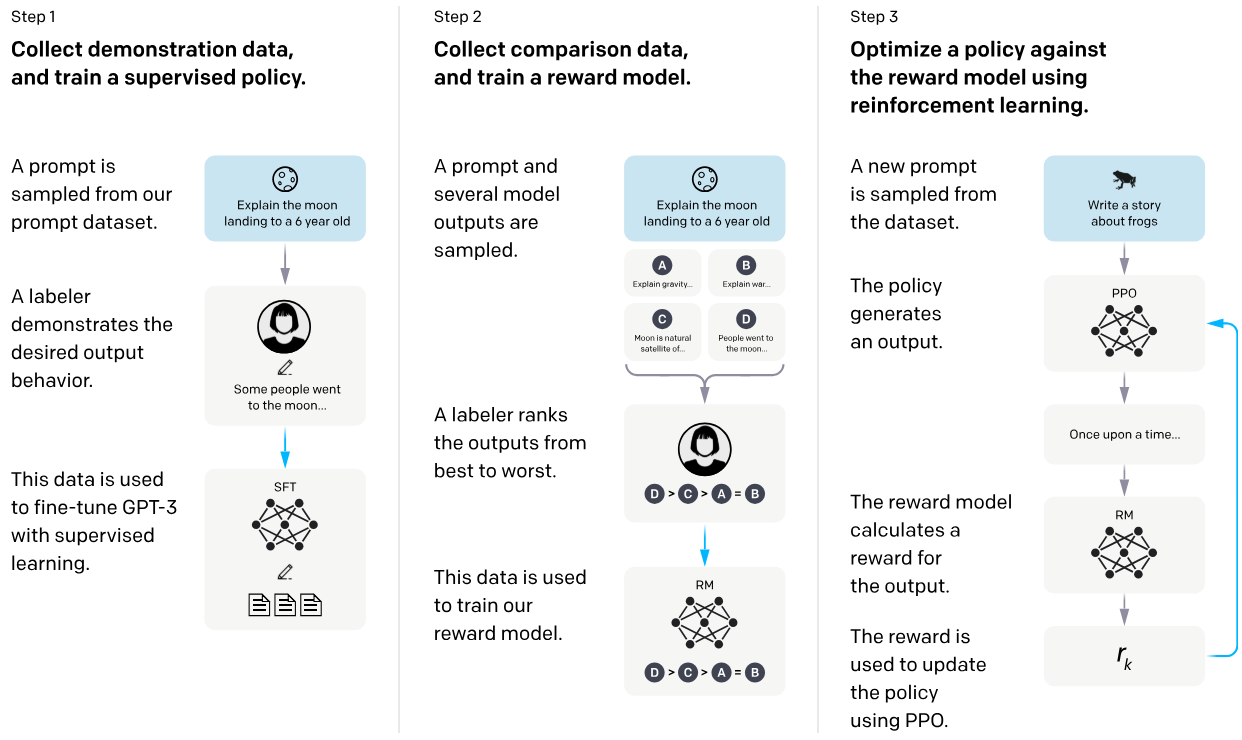
As illustrated above, taking the task of summary generation as an example, it shows how reinforcement learning based on human feedback can be used to ultimately train and complete the InstructGPT model. It mainly consists of three steps:
- Collecting Human Feedback: Using an initial model to generate multiple different summaries for a sample, humans then rank these summaries based on effectiveness, resulting in a set of ranked summary samples.
- Training the Reward Model: Using the sample set obtained from step 1, a model is trained where the input is an article and its corresponding summary, and the output is a score for that summary.
- Training the Policy Model: Using the initial policy model to generate a summary for an article, the reward model then scores this summary. These scores are used to re-optimize the policy model using the PPO algorithm.
Method details below.
Supervised Fine-Tuning (SFT)
SFT can be understood as manually annotating a batch of data, then fine-tuning GPT-3 with it. However, it’s worth mentioning that the annotated data here is fundamentally different from the few-shot format used by GPT-3 for downstream tasks previously.
In GPT-3, the few-shot learning for the same downstream task usually involves a fixed way of describing the task, and it requires humans to explore which task description is better. Clearly, there’s a significant gap between this mode and the real-world scenario of how users interact with GPT-3. Users do not adopt a fixed task description when asking questions to GPT-3; instead, they express their needs in their own conversational habits. The data annotated in InstructGPT’s SFT is precisely aimed at bridging this gap between model predictions and user expression habits. During the annotation process, they sampled a large number of downstream task descriptions from real user requests to GPT-3, then had annotators continue the task description to obtain high-quality answers for the questions. These real user requests are also known as instructions for a task, which is the core idea of InstructGPT: “instruction-based fine-tuning based on human feedback.”
Reward Modeling (RM)
Starting from the SFT model with the last non-embedding layer removed, a model was trained to input prompts and responses and output a scalar reward. In this paper, only the 6B RM was used, as this saved substantial computational resources, and it was found that training the 175B RM might be unstable, thus unsuitable to serve as a reward function during RL.
In the method of Stiennon et al. (2020), the RM was trained on a comparison dataset that compared the outputs of two models on the same input. Using cross-entropy loss, the comparisons were taken as labels—the difference in rewards represents the log odds that human annotators prefer one response over another. To accelerate the collection of comparisons, annotators were shown K = 4 to K = 9 responses to rank. Specifically, the loss function for the reward model is:
\[loss(θ) = - \frac{1}{2K} E_{(x,y_u,y_l) \sim D}[ \log(\sigma(r_θ(x, y_u) - r_θ(x, y_l)))]\]where \( r_θ(x,y) \) is the scalar output of the reward model for prompt \( x \) and completion \( y \) with parameters \( θ \), \( y_w \) is the more preferred completion out of \( y_w \) and \( y_l \), and \( D \) is the dataset of human comparisons.
Reinforcement Learning from Human Feedback(RLHF)
The SFT model was fine-tuned using PPO. The environment was a bandit setting that provided a random customer prompt and expected a response to the prompt. Given a prompt and response, it would generate a reward based on the reward model and end the episode. Additionally, a per-token KL penalty from the SFT model was added at each token to mitigate over-optimization on the reward model. The value function was initialized from RM. These models are referred to as “PPO.”
Experiments mixed pre-trained gradients into PPO gradients to fix performance regressions on public NLP datasets. These models are referred to as “PPO-ptx.” During RL training, the following combined objective function was maximized:
\[objective(ϕ) = \mathbb{E}_{(x,y) \sim D_{\pi^{\text{RL}}_{ϕ}}}[r_θ(x, y)] - \beta \log \left( \frac{\pi^{\text{RL}}_{ϕ}(y|x)}{\pi^{\text{SFT}}(y|x)} \right) + \gamma \mathbb{E}_{x \sim D_{\text{pretrain}}} \left[ \log(\pi^{\text{RL}}_{ϕ}(x)) \right]\]where \(\pi^{\text{RL}}{\phi}\) is the RL policy learned. \( (\pi)^{\text{SFT}} \) is the supervised training model, and \(D{\text{pretrain}}\) is the pre-training distribution. The KL reward coefficient \( \beta \) and the pre-training loss coefficient \( \gamma \) respectively control the intensity of the KL penalty and the pre-trained gradients. For the “PPO” model, \( \gamma \) is set to 0.
5.2 Conclusion
Overall, InstructGPT stands out from the previous GPT series in several noteworthy ways:
- It addresses the alignment issue between GPT-3’s outputs and human intentions.
- The model, rich in world knowledge, is trained to learn “human preferences.”
- Annotators noticeably perceive InstructGPT’s outputs to be better and more reliable than GPT-3’s.
- InstructGPT shows improved performance in terms of authenticity and richness.
- InstructGPT better controls the generation of harmful content, although improvements in “bias” are not significantly evident.
- It maintains strong performance on public benchmark datasets after instruction-based fine-tuning.
- InstructGPT exhibits surprising generalizability, performing well on tasks lacking human instruction data.
6. References
[1] Brown, T.B. et al. (2020) ‘Language models are few-shot learners’. arXiv. Available at: https://doi.org/10.48550/arXiv.2005.14165.
[2] Child, R. et al. (2019) ‘Generating long sequences with sparse transformers’. arXiv. Available at: https://doi.org/10.48550/arXiv.1904.10509.
[3] Ouyang, L. et al. (2022) ‘Training language models to follow instructions with human feedback’. arXiv. Available at: https://doi.org/10.48550/arXiv.2203.02155.
[4] Radford, A., Narasimhan, K., Salimans, T. and Sutskever, I., 2018. Improving language understanding by generative pre-training.
[5] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. and Sutskever, I., 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8), p.9.
[6] Stiennon, N. et al. (2022) ‘Learning to summarize from human feedback’. arXiv. Available at: https://doi.org/10.48550/arXiv.2009.01325.
[7] Wang, Q. et al. (2019) ‘Learning deep transformer models for machine translation’. arXiv. Available at: https://doi.org/10.48550/arXiv.1906.01787.