
Map-Reduce Performance Landscape
In this project, we conducted a detailed examination of the computational complexities of the Jaccard and Cosine similarity measures when applied to the task of calculating all-pair similarities across a set of text documents. We also explored how these computations can be optimized using the map-reduce computing framework. You may download it here.
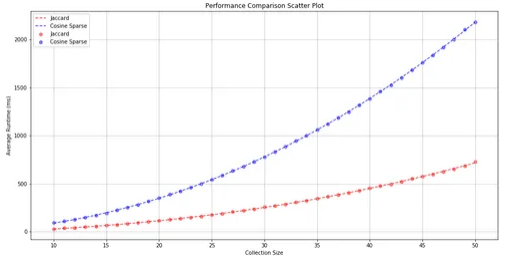
Initially, we delved into the time complexity associated with both the Jaccard and Cosine similarity measures. As anticipated, analysis revealed that both measures exhibit quadratic time complexity. However, it was observed that the Jaccard similarity measure typically executes more rapidly than its Cosine counterpart. This difference in performance can primarily be attributed to the lower computational coefficients associated with the Jaccard measure.
Subsequently, we shifted focus to assessing how the map-reduce paradigm influences the performance of these algorithms. The central aim was to determine the most efficient configuration of mapper and reducer processes. To achieve this, we constructed a three-dimensional plot: the number of mapper and reducer processes were varied along the x and y axes, respectively, with computation time represented on the z-axis. We highlighted critical points—both maxima and minima—on this plot for easier reference. Color coding and transparency were applied to the plot surfaces to enhance readability, addressing the limitations of matplotlib’s 3D plotting features.
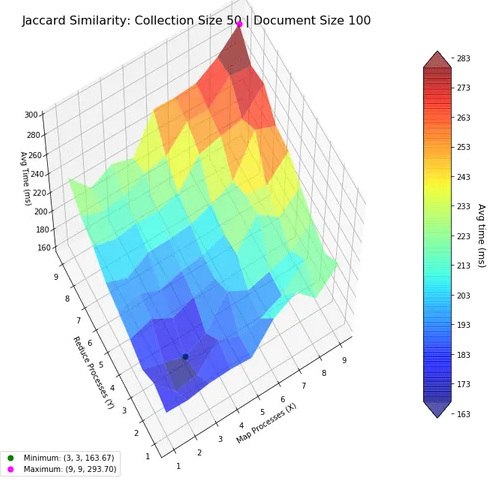
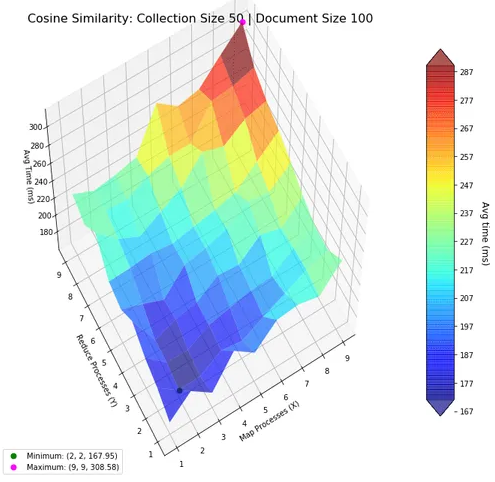
Our findings indicate that for smaller collections of documents (comprising approximately 50 files, each containing about 100 words), a reduced number of mapper-reducer processes is most effective. This configuration minimizes the computational overhead, which otherwise worsens performance when excessive processes are employed.
Conversely, with larger datasets, the data showed an increase in the optimal number of processes, particularly on the mapper side. This suggests that the primary bottleneck in the map-reduce setup for these computations is related to the mapping phase rather than the reducing phase. Such insights are crucial for optimizing processing time and resource usage in large-scale text analysis.
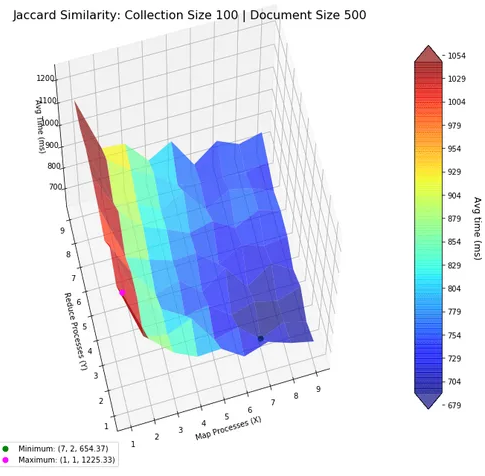
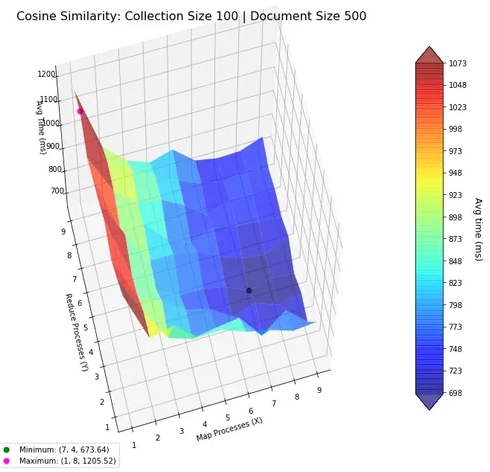
These analyses were supported by custom functions designed in Python using the matplotlib library. This programming approach facilitated the generation of the necessary visual plots, which were made both colored and partially transparent to aid in visualization, despite the challenges posed by the lack of interactivity in a Jupyter Notebook environment. This methodological approach not only underscores the flexibility of Python in computational research but also highlights the practical challenges and considerations in deploying the map-reduce model for complex data analysis tasks.